




The first part of the series on preservation of scientific data discussed the challenges to generate adequate scientific data from sample. The next step is data management. In its simplest form, the data must be documented, digitized and stored in back ups or storage systems like the hard drives. An one time bout of data like those associated with earthquakes or astronomical phenomenon can be compressed and stored in this way.
However, the information management needs another crucial step before storage. This was the need of the hour as pointed out the by the recent research in two different fields of science. The first one is the Large Hadron Collider (LHC) experiment. Unable to keep up with the speed of collisions, new software has been designed to filter out the crucial data out of the available data.
The old ‘preserve every data’ approach has been replaced by ‘preserve all crucial stuff and random from the rest’. Once the experiment gets into full swing, the randomness of the data to be preserved will further reduce in proportion. In its peak moments of intensity at full beam, the data to be preserved will be selected on the ratio 1:10000 collisions.
This is not a single experiment handling larger data. The realms of genome biology have necessitated significant changes in hard disk drive capacities for the past decades. There is no wonder if the hard disk drives are led fast to extinction with the present pace of DNA sequencing methodologies. The number of base pair sequencing data which can be saved per dollar has increased drastically with the advanced DNA sequencers. The figure is found to double in every five months in the current situations. Previously this happened once in 14 months. The DNA sequencing firms are trying their best to find improved ways of storage.
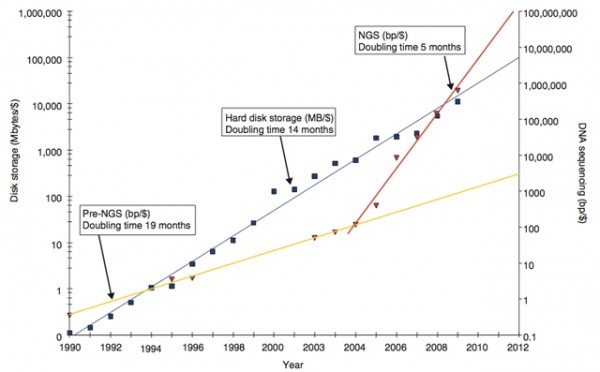

Newer methods of DNA sequencing out drive the ‘hard disk drives’ with data.
Genome Biology
All the data cannot be stored. Hence researchers are to be more judgmental in choosing the data to be kept and the means to keep the data.
A good example illustrating the hurdles of digitizing data is the digital camera. Images are formed when light rays hit a specific place at a certain time and are recorded. The images in a low end camera are not fine tuned. High end devices provide corrections for the bad pixels and minor hardware mistakes. Images are stamped with the date and time only on setting the clock in the camera. At last, the external data needs to be in the format that can be processed and interpreted. Hence digitization does not guarantee an accurate record.
Just as this case, most of the scientific instruments fail to provide accurate ‘raw data’ leave alone preservation. The processing of scientific data is aimed to provide corrections for the equipment defects.
The spectrophotometer is used to analyze the purity and measure the DNA concentration in solutions by the absorption spectra at specific wavelengths. The absorption values are subjected to equations which convert them into units of concentration. The advanced spectrophotometers has inbuilt calculations feature that allows the user to get the value through a single button. The ‘raw data’ does not exist any more and what we get as the output is a usable and crucial data.
DNA sequencers are a little advanced than these equipments. The original data is a graph depicting the light emission patterns. The graphs simply won’t give a conclusion and needs a metadata analysis. The data is converted to an informative form which can be interpreted easily like the Sanger sequencing file.


A Sanger sequencing file
An experienced researcher can infer the bases from the curves of the graph. However the human genome mapping required more sophisticated and fast decision makers to identify the base sequences. The HGP could not have been finished with manual tracing. Algorithms were employed to identify the base calls. The scoring was done for each base value. Based on these data, analysis and proper identification patterns were established which narrowed the process of decision making by removing raw data.
The National Center for Biotechnology Information (NCBI) stores the genome data. The center has ceased collecting trace data after the HGP. The researchers are advised to retain the raw data for the non genomic sequences. The original data from the past decades when digitization was unheard of, is simply non retrievable.
The more advanced equipments which need large data handling include the satellite equipments. NASA takes measures to calibrate the instruments before use to correct for errors such as bad pixels and only the corrected data is given to the researchers. The recent Kepler data is supposed to be free from errors of the hardware malfunctions.
Another example is the Jason-1, the NASA satellite used to measure ocean levels. The satellite is prone to orbital decay which in the long run will make it nearer to the oceans. The direct data from the satellite cannot be used and for analyzing ocean levels, one needs to verify the adjusted NASA data.
The decision on how much of the original data is to be stored therefore requires individual case studies and is dependant on the research hypothesis. This can be ascertained by the two common controversies. The first one is from the climate sciences regarding the differences in surface temperature measurements of lower atmosphere and the measurements derived from crude satellite data. However after identifying the sources of variation and applying corrections for the satellite data, the figures were found to be uniform.
Another calibration defect was identified in the early June of the year in the data of the WMAP satellite of NASA. The satellite measures and produces the images of the microwave radiation background from Big Bang. The original calibration of the satellite was accepted by cosmologists to be proof of energy and dark matter. However, with a different set of calibration it is possible to get results which can turn the results dramatically disproving the existence of dark energy.
The raw scientific data should be accessible for such findings about the effects of calibration defects. However, other areas of science are heavily depending on decision making based on processed data. These are supported by the assumption that the data can exist for longer duration to argue and make accurate conclusions. But this is never tested with any scientific data so far as to reach a definite conclusion about the use of storage of raw data.